Hace poco el proyecto OpenAI, que desarrolla proyectos públicos en el campo de la inteligencia artificial, ha publicado novedades relacionadas con el sistema de reconocimiento de voz Whisper, el cual es un sistema de reconocimiento automático de voz (ASR) entrenado en 680.000 horas de datos supervisados multilingües y multitarea recopilados de la web.
Se afirma que para el habla en inglés, el sistema proporciona niveles de confiabilidad y precisión de reconocimiento automático cercanos al reconocimiento humano.
Mostramos que el uso de un conjunto de datos tan grande y diverso conduce a una mayor solidez a los acentos, el ruido de fondo y el lenguaje técnico. Además, permite la transcripción en varios idiomas, así como la traducción de esos idiomas al inglés. Somos modelos de código abierto y código de inferencia que sirven como base para crear aplicaciones útiles y para futuras investigaciones sobre procesamiento de voz sólido.
Sobre el modelo (como ya se mencionó) se entrenó utilizando 680 000 horas de datos de voz recopilados de varias colecciones que cubren diferentes idiomas y áreas temáticas. Alrededor de 1/3 de los datos de voz involucrados en el entrenamiento están en idiomas distintos al inglés.
El sistema propuesto maneja correctamente situaciones como la pronunciación con acento, la presencia de ruido de fondo y el uso de jerga técnica. Además de transcribir el habla en texto, el sistema también puede traducir el habla de un idioma arbitrario al inglés y detectar la apariencia del habla en la transmisión de audio.
Los modelos se forman en dos representaciones: un modelo para el idioma inglés y un modelo multilingüe que admite español, ruso, italiano, alemán, japonés, ucraniano, bielorruso, chino y otros idiomas. A su vez, cada vista se divide en 5 opciones, que difieren en tamaño y número de parámetros cubiertos en el modelo.
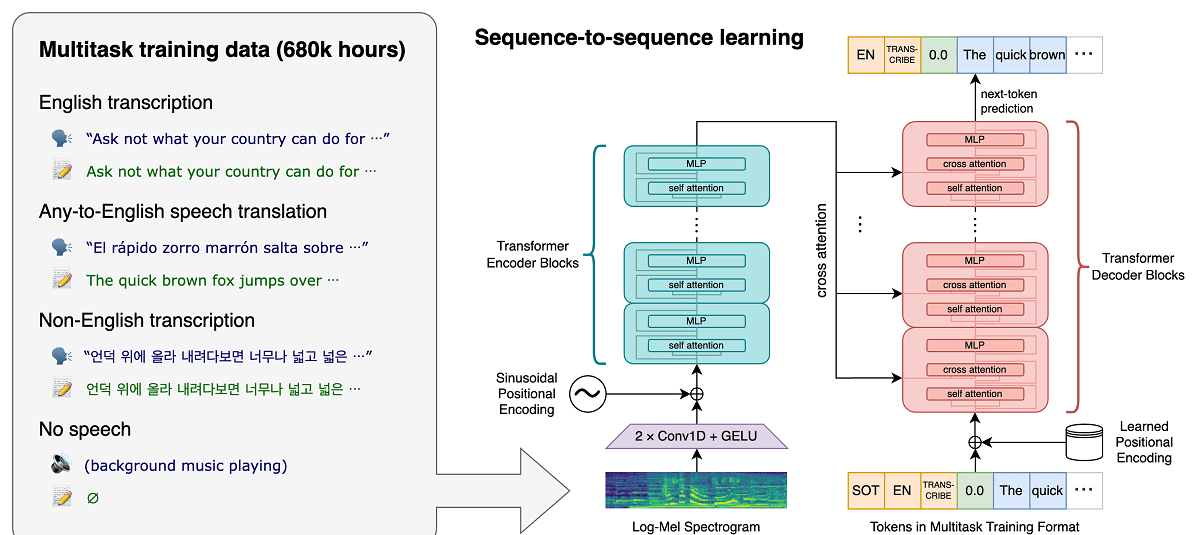
La arquitectura Whisper es un enfoque simple de extremo a extremo, implementado como un transformador codificador-decodificador. El audio de entrada se divide en fragmentos de 30 segundos, se convierte en un espectrograma log-Mel y luego se pasa a un codificador. Se entrena un decodificador para predecir el subtítulo de texto correspondiente, entremezclado con tokens especiales que dirigen al modelo único para realizar tareas como identificación de idioma, marcas de tiempo a nivel de frase, transcripción de voz multilingüe y traducción de voz al inglés.
Cuanto mayor sea el tamaño, mayor será la precisión y la calidad del reconocimiento, pero también mayores serán los requisitos para el tamaño de la memoria de video de la GPU y menor será el rendimiento. Por ejemplo, la opción mínima incluye 39 millones de parámetros y requiere 1 GB de memoria de video, mientras que la opción máxima incluye 1550 millones de parámetros y requiere 10 GB de memoria de video. La variante mínima es 32 veces más rápida que la máxima.
El sistema utiliza la arquitectura de red neuronal «Transformador», que incluye un codificador y un decodificador que interactúan entre sí. El audio se divide en fragmentos de 30 segundos, que se convierten en un espectrograma log-Mel y se envían al codificador.
El resultado del trabajo del codificador se envía al decodificador, que predice una representación de texto mezclada con tokens especiales que permiten resolver tareas como la detección de idioma, la contabilidad de la cronología de la pronunciación de frases, la transcripción del habla en diferentes idiomas y la traducción al inglés en un modelo general.
Cabe mencionar que el rendimiento de Whisper varía mucho según el idioma, por lo que el que presenta un mejor entendimiento es el inglés el cual cuenta cuatro con versiones solo en inglés, que al igual que los demás modelos de otros idiomas ofrecen ventajas y desventajas de velocidad y precisión.
Finalmente si estás interesado en poder conocer más al respecto, puedes consultar la publicación original en este enlace, mientras que si estás interesado en el código fuente y los modelos entrenados los puedes consultar en este enlace.
El código de implementación de referencia basado en el marco PyTorch y un conjunto de modelos ya entrenados están abiertos, listos para usar. El código es de código abierto bajo la licencia MIT y cabe mencionar que se require del uso de la biblioteca de ffmpeg.
from Desde Linux https://ift.tt/7wS40Ap
via IFTTT



No hay comentarios.:
Publicar un comentario